Compute the MLEs and log-likelihood for the STAR linear model. The regression coefficients are estimated using least squares within an EM algorithm.
Usage
lm_star(
formula,
data = NULL,
transformation = "np",
y_max = Inf,
sd_init = 10,
tol = 10^-10,
max_iters = 1000
)Arguments
- formula
an object of class "
formula" (seelmfor details on model specification)- data
an optional data frame, list or environment (or object coercible by as.data.frame to a data frame) containing the variables in the model; like
lm, if not found in data, the variables are taken fromenvironment(formula)- transformation
transformation to use for the latent data; must be one of
"identity" (identity transformation)
"log" (log transformation)
"sqrt" (square root transformation)
"np" (nonparametric transformation estimated from empirical CDF)
"pois" (transformation for moment-matched marginal Poisson CDF)
"neg-bin" (transformation for moment-matched marginal Negative Binomial CDF)
"box-cox" (box-cox transformation with learned parameter)
- y_max
a fixed and known upper bound for all observations; default is
Inf- sd_init
add random noise for EM algorithm initialization scaled by
sd_inittimes the Gaussian MLE standard deviation; default is 10- tol
tolerance for stopping the EM algorithm; default is 10^-10;
- max_iters
maximum number of EM iterations before stopping; default is 1000
Value
an object of class "lmstar", which is a list with the following elements:
coefficientsthe MLEs of the coefficientsfitted.valuesthe fitted values at the MLEsg.hata function containing the (known or estimated) transformationginv.hata function containing the inverse of the transformationsigma.hatthe MLE of the standard deviationmu.hatthe MLE of the conditional mean (on the transformed scale)z.hatthe estimated latent data (on the transformed scale) at the MLEsresidualsthe Dunn-Smyth residuals (randomized)residuals_repthe Dunn-Smyth residuals (randomized) for 10 replicateslogLikthe log-likelihood at the MLEslogLik0the log-likelihood at the MLEs for the *unrounded* initializationlambdathe Box-Cox nonlinear parameterand other parameters that (1) track the parameters across EM iterations and (2) record the model specifications
Details
Standard function calls including
coefficients, fitted, and residuals apply.
Fitted values are the expectation at the MLEs, and as such are not necessarily count-valued.
Note
Infinite latent data values may occur when the transformed Gaussian model is highly inadequate. In that case, the function returns the *indices* of the data points with infinite latent values, which are significant outliers under the model. Deletion of these indices and re-running the model is one option, but care must be taken to ensure that (i) it is appropriate to treat these observations as outliers and (ii) the model is adequate for the remaining data points.
References
Kowal, D. R., & Wu, B. (2021). Semiparametric count data regression for self‐reported mental health. Biometrics. doi:10.1111/biom.13617
Examples
# Simulate data with count-valued response y:
sim_dat = simulate_nb_lm(n = 100, p = 5)
y = sim_dat$y; X = sim_dat$X[,-1] # remove intercept
# Fit model
fit_em = lm_star(y ~ X)
# Fitted coefficients:
coef(fit_em)
#> (Intercept) X1 X2 X3 X4
#> -0.01141440 0.42939946 0.47275421 -0.17158694 0.08370283
# Fitted values:
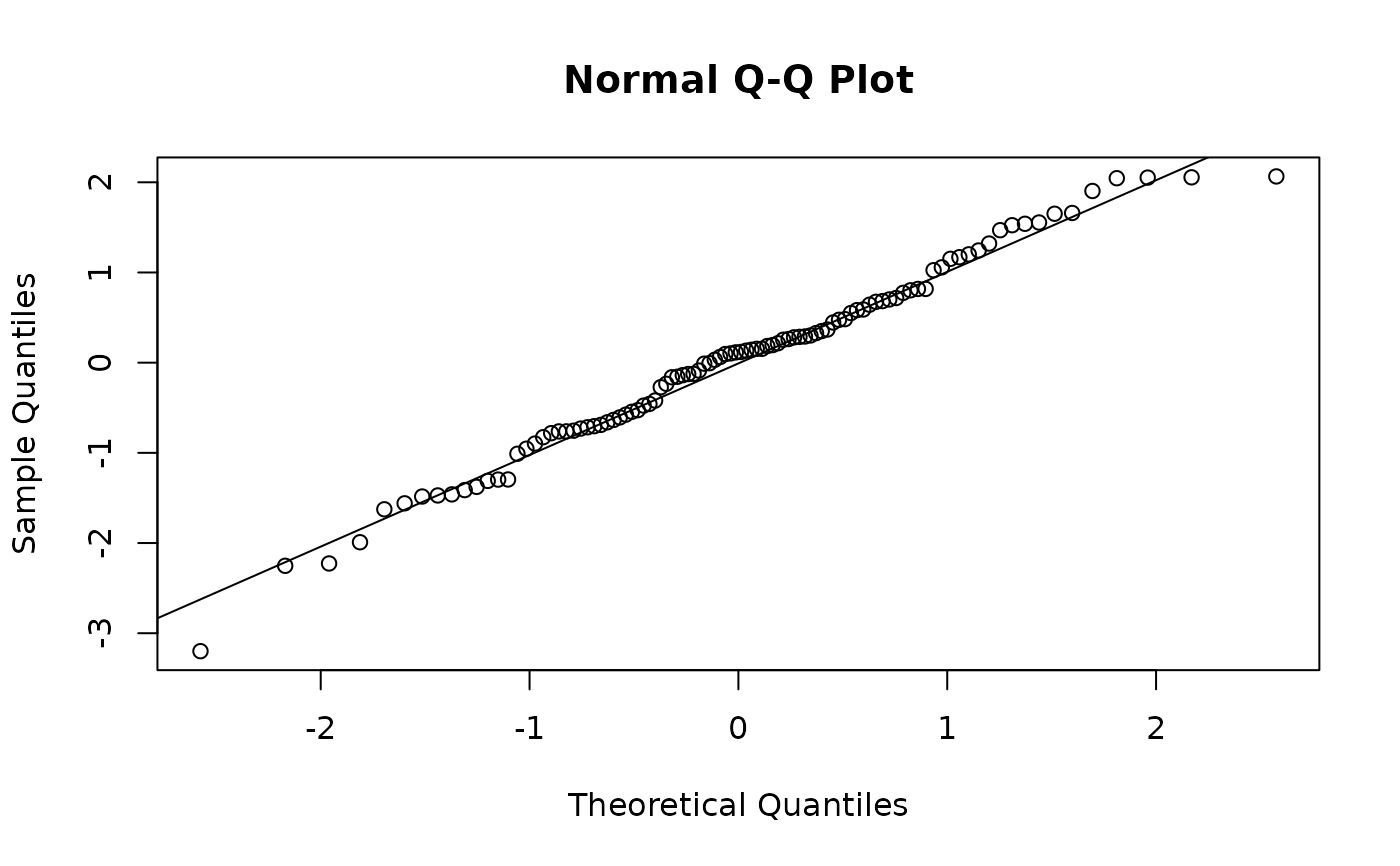
y_hat = fitted(fit_em)
plot(y_hat, y);
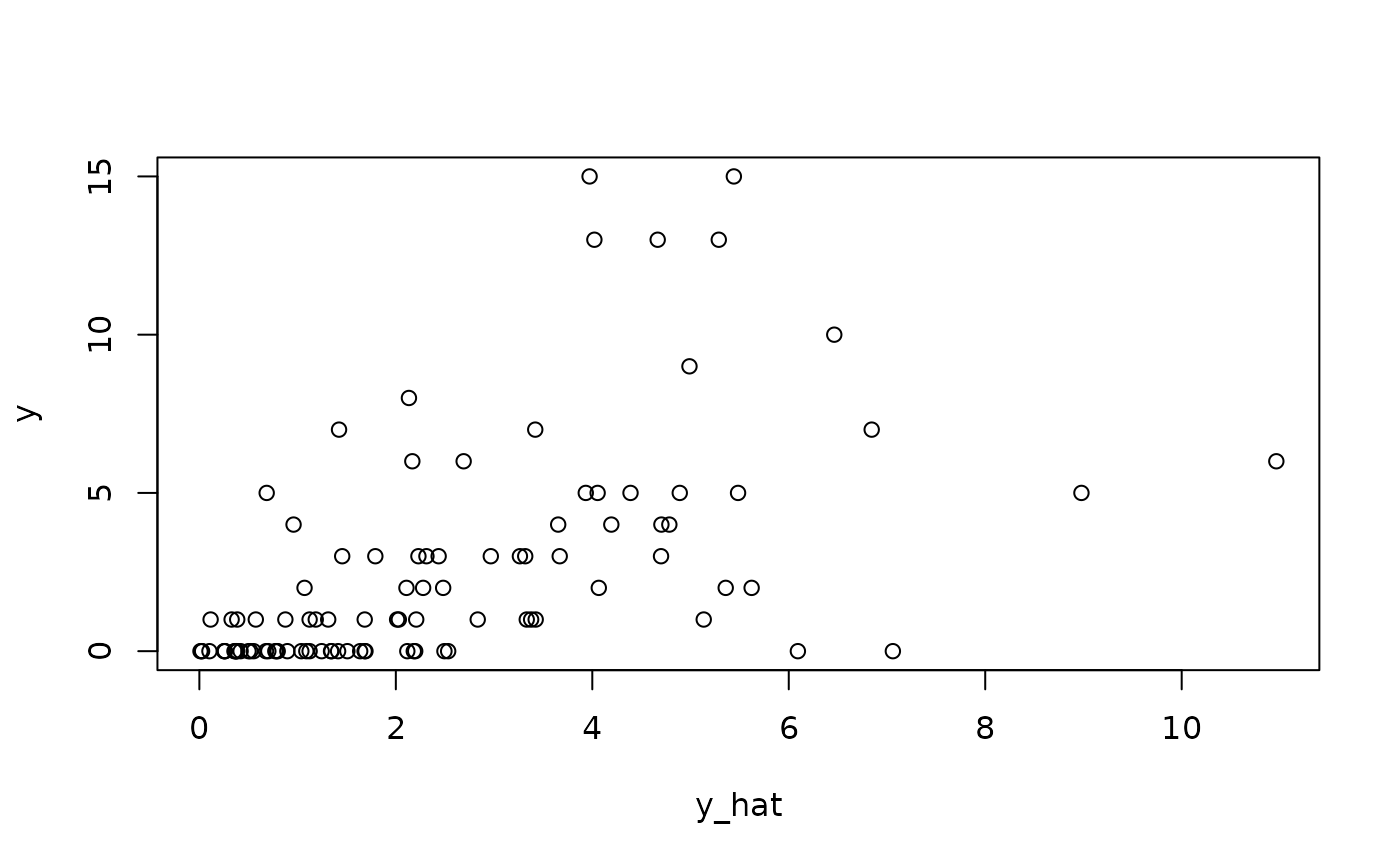 # Residuals:
plot(residuals(fit_em))
# Residuals:
plot(residuals(fit_em))
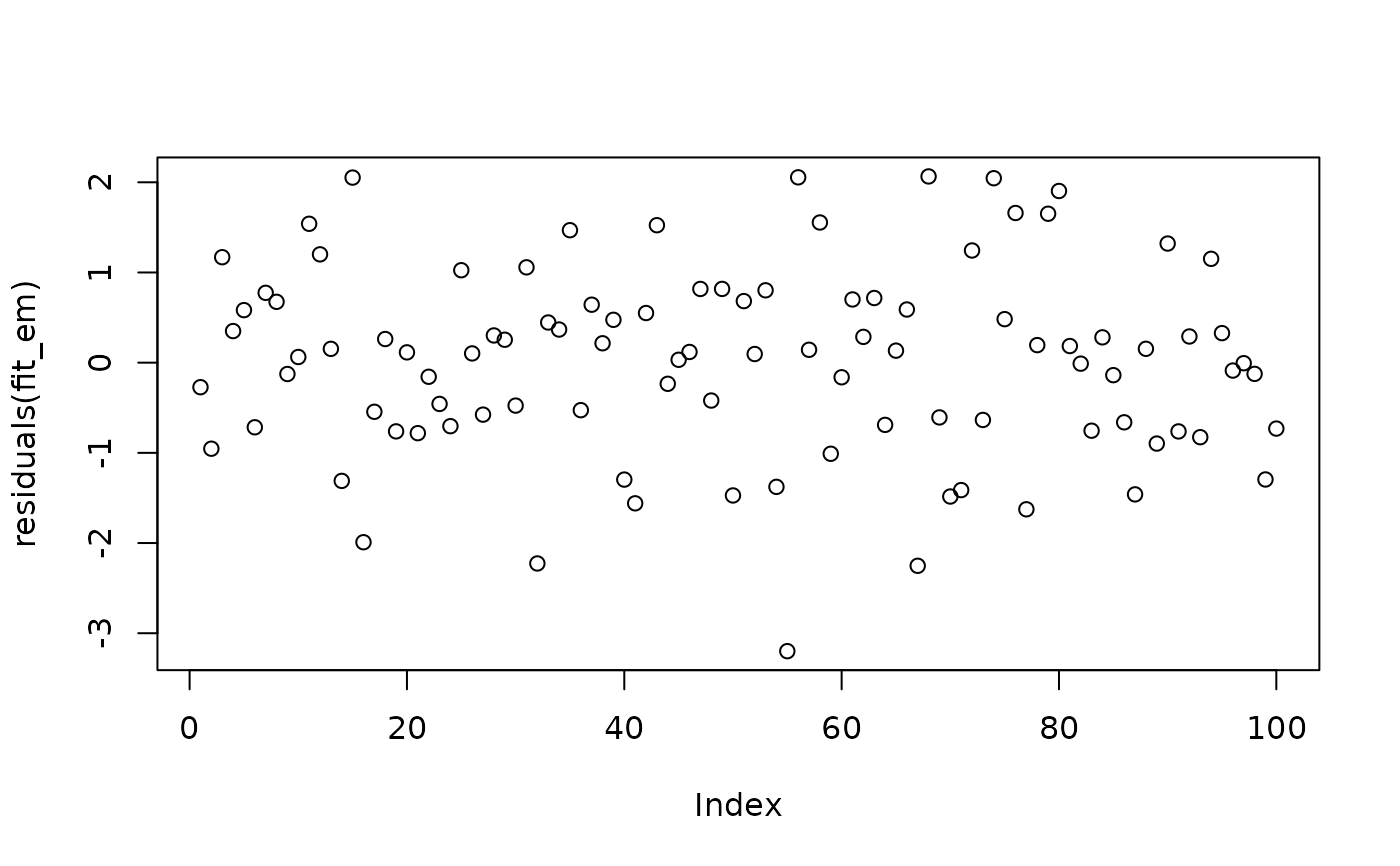 qqnorm(residuals(fit_em)); qqline(residuals(fit_em))
qqnorm(residuals(fit_em)); qqline(residuals(fit_em))